Serverless Computing
Serverless Computing is an event-driven, a compute-on-demand experience that extends existing cloud provider application platforms with capabilities to implement code triggered by events occurring in virtually any cloud provider or 3rd party service as well as on-premises systems. Serverless Computing allows developers to take action by connecting to data sources or messaging solutions, thus making it easy to process and react to events. Serverless Computing elements scale based on demand and you pay only for the resources you consume.
The 111 online project recently carried out an investigation into serverless computing. The investigation was a fact-finding task to see how serverless computing would be able to complement the existing application architecture and derive any benefits we could utilise in the project.
We would only do the testing using Microsoft Azure Functions as we already had an account and were familiar with the service offering.
We chose the Feedback API to turn Serverless first. The API takes user entry from the application and feeds this into an SQLite database and returns a response to the user to say success or failure.
Within Azure Functions there appears to be no method of storing an SQLite database, so we used Azure Table Storage. This was a beneficial selection as Azure Functions have inbuilt methods for Azure Table Storage interaction.
The First Version
The first version that was developed used the existing model. The data flow would send the request, log the feedback and finally respond to the user. This was very easy to do within the Azure Function and was not many lines of code to complete.
The Second Version
The second version we decided to output to another service as well as the Azure Table Storage. So the data flow would now send the request, log the feedback, post data to a 3rd party and finally respond to the user. This did not test as well as the first version due to the 3rd party integration. Another version was required.
The Final Version (so far)
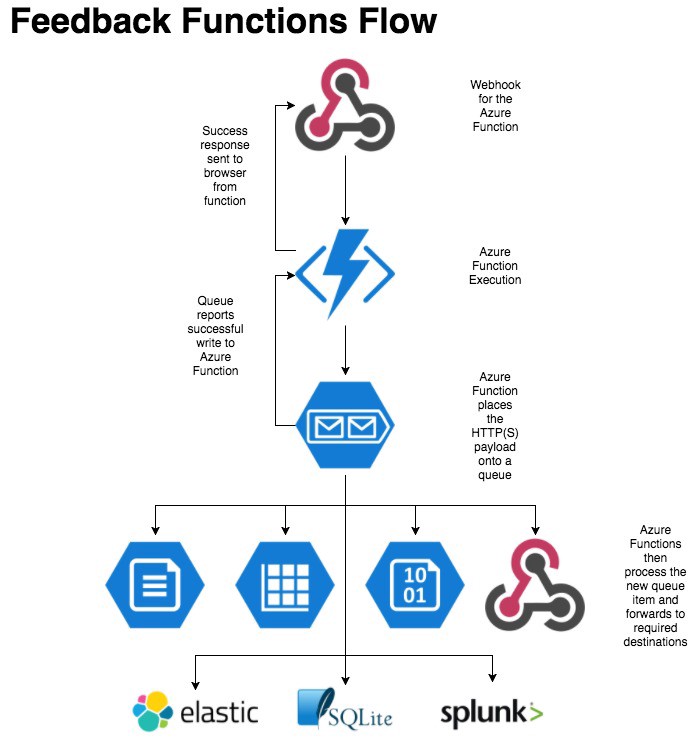
The final version was setup using Azure Storage Queues. This affords us greater flexibility in what we do with our data and allows the user to carry on without waiting. The data flow would now send the request, log the request to a queue, respond to the user, post data to the Azure Table Storage and finally post data to the 3rd party.
This version allows us to manage where our data goes internally. We can add additional functions to post data to various endpoints as new items are added to the queue. However, using functions in this way requires the use of a trigger function to execute the additional process functions.
Testing
We tested the 3 versions as we went along. The tests were performed using Apache Benchmark that sent 2000 requests at 2 different concurrent rates of 5 and 10. This would simulate users hitting the application and their average response times. For the tests, we took the 95th percentile reading to provide our measurements.
When the current application with an SQLite database was hit with a lot of requests we experienced the 95th percentile of 30 seconds with quite a few errors. Using the new versions, the timings were; version 1 was 0.249 seconds, version 2 was 2.25 seconds and version 3 was 0.565 seconds.
Key Value Lookups
During the investigation, we also developed 2 key-value lookup functions. The first being a postcode lookup and the second a next step lookup. The main finding of this is the way you partition the data. We initially uploaded the data with the same partition id which caused all of the data to be placed on the same node. However, we then switched the partition id to be the postcode and the question code. This allowed the data to be split across multiple data nodes allowing quicker read access to the data and improving performance.
Costs
We can all understand the costs. Our bosses, finance teams and anyone else who wants to save is always asking us to save it. Well, the testing for this Serverless Testing comes in at a high cost of £0.04. Yes, that’s right 4 pence!! It is also only this high as it’s a minimum cost for a number of requests we tested with which is around 70,000+ of them. That and that is the minimum billing amount.
Overall it makes sense
The overall investigation into Serverless Computing and the cloud make sense. It is the true purpose of cloud computing and using resources based on execution of a request not just hosting virtual servers in someone else’s Data Centre. You can provision dedicated capacity and, yes, it does give you a small performance boost. But the pay-per-execution method is just as responsive and once the scaling heuristic’s kick in that machine scaling is not yours to handle. Giving the flexibility that modern applications require.